FAST: Quick Application Launch on Solid-State Drives — Joo et al.
| 연구 단계Research Phase | FAST 논문 적용Application in FAST Paper |
|---|---|
| 1. 시스템 입출력 관찰System I/O Observation | Blktrace로 애플리케이션 cold start 시 블록 I/O 트레이스 수집Collected block I/O traces during application cold start via Blktrace — 앱 실행 시 발생하는 수천 개의 블록 요청을 커널 레벨에서 기록— Recorded thousands of block requests at kernel level during app launch |
| 2. 특이 패턴 발견Pattern Discovery | Cold start 시 페이지 폴트 순서 및 I/O 요청 순서가 매 실행마다 동일 (deterministic)Page fault and I/O request order identical across every cold start (deterministic) — 같은 앱을 반복 실행하면 블록 요청 시퀀스가 변하지 않음을 발견— Discovered that block request sequences remain unchanged across repeated app launches — page fault 발생 시 CPU는 대기하고 저장장치만 동작함 → CPU 연산 중에는 저장장치는 유휴 상태— During a page fault CPU idles while only storage works → during CPU computation storage sits idle |
| 3. 개선 아이디어Improvement Idea | CPU 연산 시간과 SSD I/O 시간을 오버랩 (동시 실행)Overlap CPU computation time with SSD I/O time (concurrent execution) — prefetcher가 I/O를 미리 발행하여, 앱이 필요로 할 때 이미 page cache에 존재하도록 함— Prefetcher issues I/O in advance so data resides in page cache when the app needs it — tlaunch ≈ max(tssd, tcpu) 로 단축 가능 |
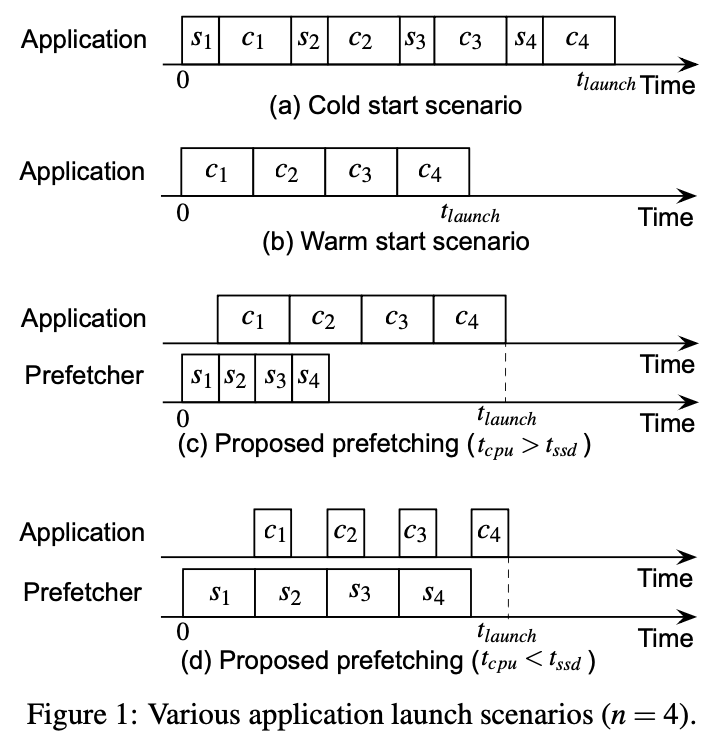
| 연구 단계Research Phase | FAST 논문 적용Application in FAST Paper |
|---|---|
| 4. 알고리즘 도출/보완Algorithm Design | LBA → 파일 역매핑 (블록 주소 → 파일명 + 오프셋 변환) 알고리즘 설계LBA → File reverse mapping (block address → filename + offset) algorithm design — 파일 시스템(EXT3)은 LBA→파일 역방향 매핑을 지원하지 않음— File system (EXT3) does not support LBA→file reverse mapping — Red-black tree 기반 LBA-to-inode map을 앱별로 구축하여 해결— Solved by building per-app LBA-to-inode map using red-black tree |
| 5. 구현Implementation | User-level FAST 시스템 구현: posix_fadvise()로 prefetch 수행User-level FAST system implementation: prefetching via posix_fadvise() — launch manager, system-call profiler, disk I/O profiler — launch sequence extractor, LBA-to-inode mapper, prefetcher generator — 커널 수정 없이 Linux 2.6.32에서 동작— Runs on Linux 2.6.32 without kernel modifications |
| 6. 시스템 구현System Integration | Linux Fedora 12 + Intel 80GB SSD 환경에서 22개 실제 앱 대상 통합 테스트Integration test with 22 real applications on Linux Fedora 12 + Intel 80GB SSD — Acrobat, Eclipse, Firefox, Gnome, Matlab, OpenOffice 등etc. |
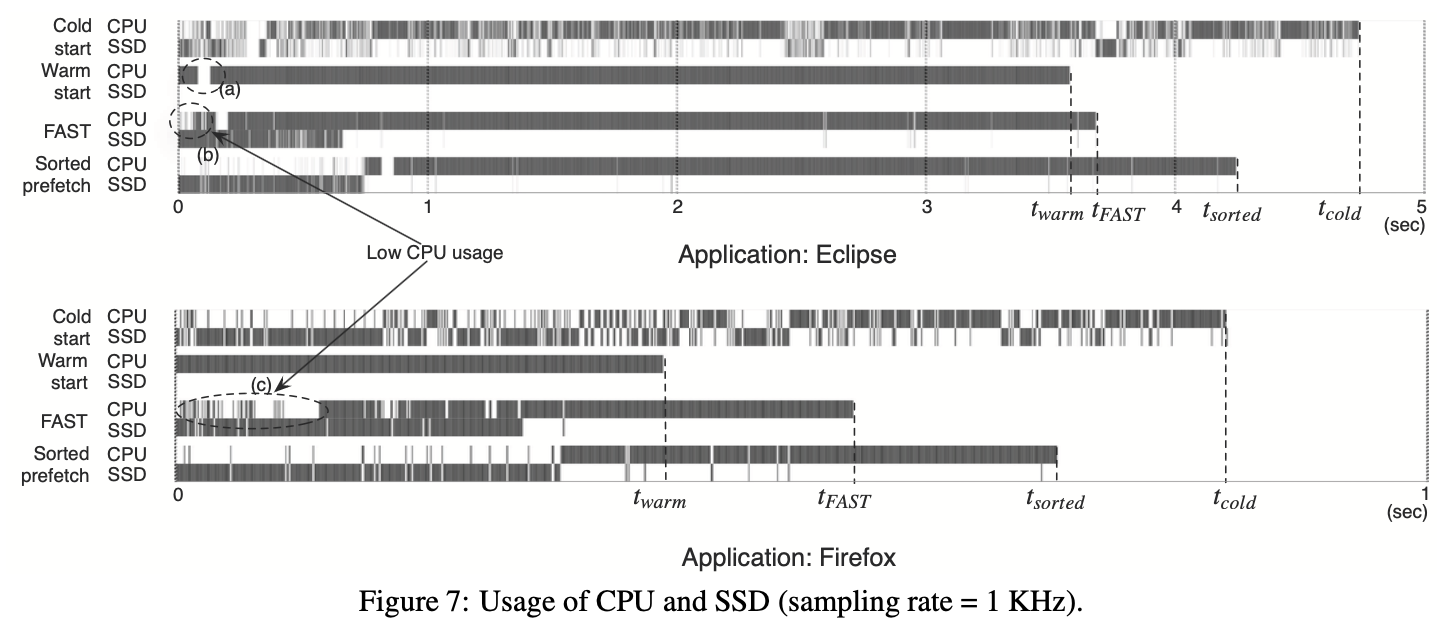
| 7. 성능평가Evaluation | Cold start 대비 평균 28% launch time 단축 (16~46% 범위)Average 28% launch time reduction vs. cold start (range: 16~46%) — miss ratio 1.6%로 prefetcher 정확도 검증— Prefetcher accuracy verified with 1.6% miss ratio — 다중 앱 동시 실행(Fig.8)에서도 성능 향상 확인 (5~20개 앱, 개선폭 20%→7%)— Performance gains confirmed under multi-app concurrent launch (Fig.8, 5~20 apps, 20%→7%) |
Enlarging I/O Size for Faster Loading of Mobile Applications — Joo et al.
| 연구 단계Research Phase | 논문 적용Application in Paper |
|---|---|
| 1. 시스템 입출력 관찰System I/O Observation | Blktrace로 모바일 앱 시작 시 블록 I/O 트레이스 수집Collected block I/O traces during mobile app launch via Blktrace — demand paging이 생성하는 I/O 패턴을 커널 레벨에서 기록— Recorded I/O patterns generated by demand paging at kernel level |
| 2. 특이 패턴 발견Pattern Discovery | Demand paging은 다양한 크기의 다수 I/O를 queue depth 1로 발행Demand paging issues many I/Os of varying sizes at queue depth 1 — Flash 스토리지의 I/O 크기 vs 대역폭이 비선형: 소형 I/O에서 대역폭이 낮고 대형 I/O에서 급격히 높아짐— Flash storage I/O size vs. bandwidth is nonlinear: low bandwidth for small I/Os, sharply higher for large I/Os — 원인: 큰 I/O일수록 eMMC 내부 다중 다이가 동시 활성화되어 병렬 처리량 증가— Cause: larger I/Os activate multiple internal dies simultaneously, increasing parallel throughput → I/O 크기를 키우면 같은 데이터량에 대해 훨씬 빠른 전송이 가능→ Enlarging I/O size enables much faster transfer for the same data volume |
| 3. 개선 아이디어Improvement Idea | Explicit loading + I/O 크기 확대를 위한 3단계 최적화3-step optimization for explicit loading + I/O size enlargement — ① I/O Reordering: working set을 LBA 순서로 정렬 (기존 기법)— ① I/O Reordering: sort working set by LBA order (prior technique) — ② I/O Merging: 인접한 청크를 병합 (기존 기법)— ② I/O Merging: merge adjacent chunks (prior technique) — ③ I/O Padding: 비연속 청크 사이에 불필요한 페이지를 삽입하여 I/O 크기를 추가 확대 (본 논문의 핵심 기여)— ③ I/O Padding: insert unnecessary pages between non-contiguous chunks to further enlarge I/O size (key contribution) |
| 4. 알고리즘 도출/보완Algorithm Design | Dynamic Programming 기반 최적 패딩 결정 알고리즘Optimal padding decision algorithm based on Dynamic Programming — Working set W = (b0, b1, …, bn-1), 패딩 벡터padding vector P = (p0, …, pn-2) — t(i,j) = min { read(i,j), t(i,s)+t(s+1,j) } — 패딩 vs 분할의 최적 트레이드오프optimal trade-off between padding vs. splitting — Storage 성능 모델: I/O 크기별 읽기 시간을 실측하여 lookup table 구축— Storage performance model: empirical read-time lookup table per I/O size |
| 연구 단계Research Phase | 논문 적용Application in Paper |
|---|---|
| 5. 구현Implementation | Explicit application loading 모듈 (pread 시스템콜 기반)Explicit application loading module (pread syscall-based) — Profiler: blktrace로 working set 수집collect working set via blktrace — Optimizer: reordering → merging → DP padding — Loader: 최적화된 I/O 시퀀스를 pread로 실행execute optimized I/O sequence via pread |
| 6. 시스템 구현System Integration | Google Nexus 5 (32GB eMMC) + 16개 Android 앱 대상 테스트Tested on Google Nexus 5 (32GB eMMC) with 16 Android apps — Chrome, Facebook, Firefox, Netflix, WhatsApp, Twitter, Skype 등etc. |
| 7. 성능평가Evaluation | 평균 I/O 크기 5.6배 증가, 앱 로딩 시간 최대 30% 단축Average I/O size increased 5.6x, app loading time reduced by up to 30% — I/O merging: 19.3% 감소, I/O padding 추가 적용: 29.9% 감소— I/O merging: 19.3% reduction; with I/O padding: 29.9% reduction — 백그라운드 I/O 간섭 하에서도 성능 이점 유지— Performance gains maintained under background I/O interference — 에너지 소비도 1/3 감소 (I/O 크기 확대로 eMMC 효율 향상)— Energy consumption also reduced by 1/3 (eMMC efficiency improved with larger I/O sizes) |

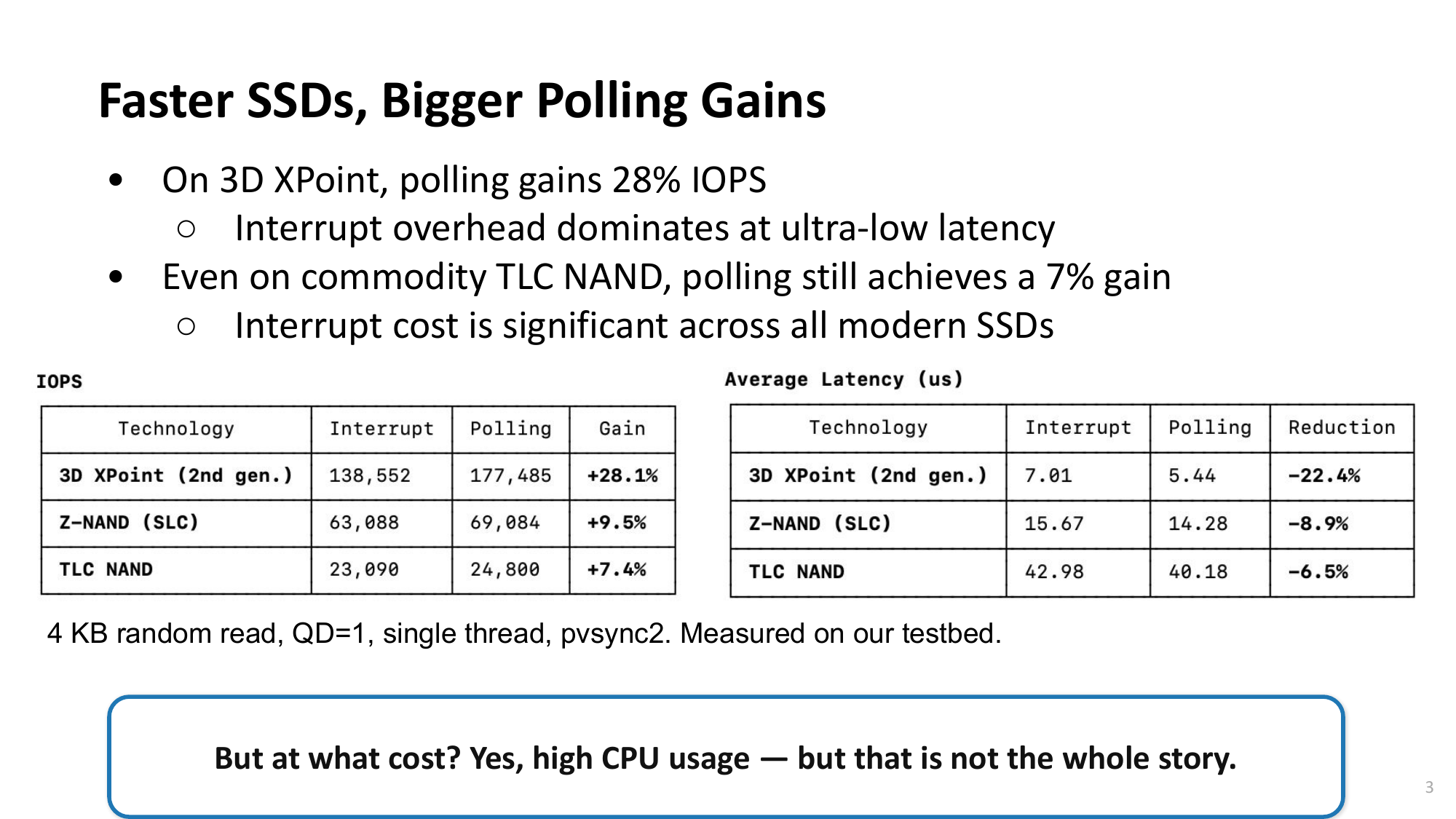
Improving Virtualized I/O Performance by Expanding the Polled I/O Path of Linux — Seo, Joo, Dutt
| 연구 단계Research Phase | 논문 적용Application in Paper |
|---|---|
| 1. 시스템 입출력 관찰System I/O Observation | 가상화 환경에서 guest OS의 I/O 경로 및 host page cache 접근 성능 측정Measured guest OS I/O path and host page cache access performance in virtualized environments — fio로 guest ↔ host page cache 간 4KB random read 처리량 측정— Measured 4KB random read throughput between guest and host page cache via fio |
| 2. 특이 패턴 발견Pattern Discovery | Host page cache (DRAM)에 데이터가 있어도 guest의 처리량이 105 MB/s에 불과Even with data in host page cache (DRAM), guest throughput was only 105 MB/s — DRAM 대역폭은 수십 GB/s인데 guest I/O 경로에서 불필요한 context switch 발생— DRAM bandwidth is tens of GB/s, yet unnecessary context switches occur in guest I/O path — 원인: guest OS는 데이터가 host SSD에 있는지 host cache에 있는지 알 수 없음— Cause: guest OS cannot determine if data resides in host SSD or host cache — 항상 저장장치에 있을 것으로 간주 → I/O submit 후 무조건 task switching 수행— Always assumes data is on storage device → unconditional task switching after I/O submit |
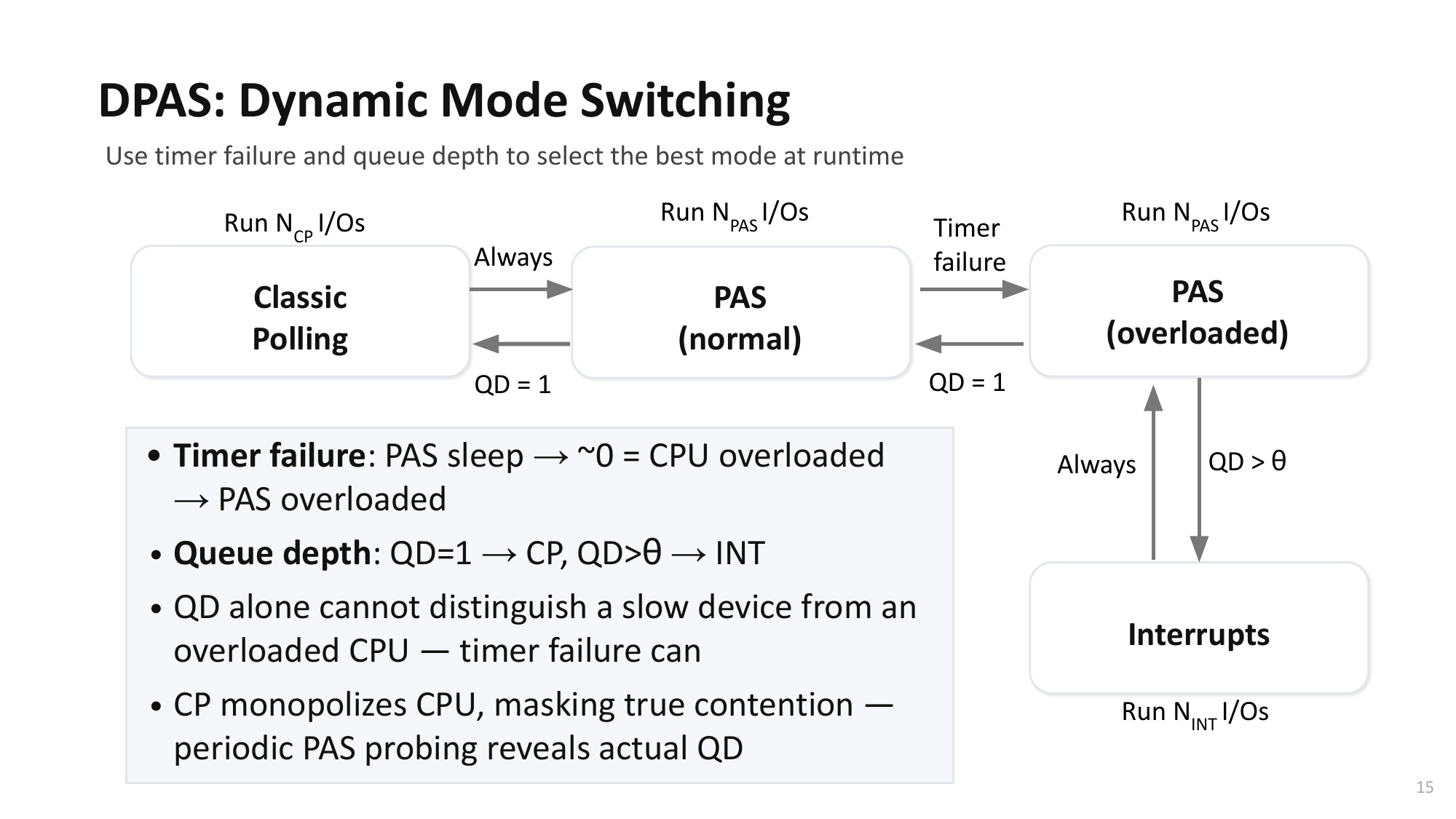
| 3. 개선 아이디어Improvement Idea | Host cache 접근 시 polling을 시도하여 context switch 오버헤드를 회피Attempt polling on host cache access to avoid context switch overhead — 데이터가 host cache에 있으면 I/O가 즉시 완료됨 → polling이 유리— If data is in host cache, I/O completes instantly → polling is advantageous — 시스템 수준 장벽: Linux 커널의 buffered I/O, mmap 경로에 poll path가 미비— System-level barrier: Linux kernel's buffered I/O and mmap paths lack poll path support — 보완책: polled I/O 경로를 buffered I/O (path ③), mmap (path ④)으로 확장— Solution: expand polled I/O path to buffered I/O (path ③) and mmap (path ④) |
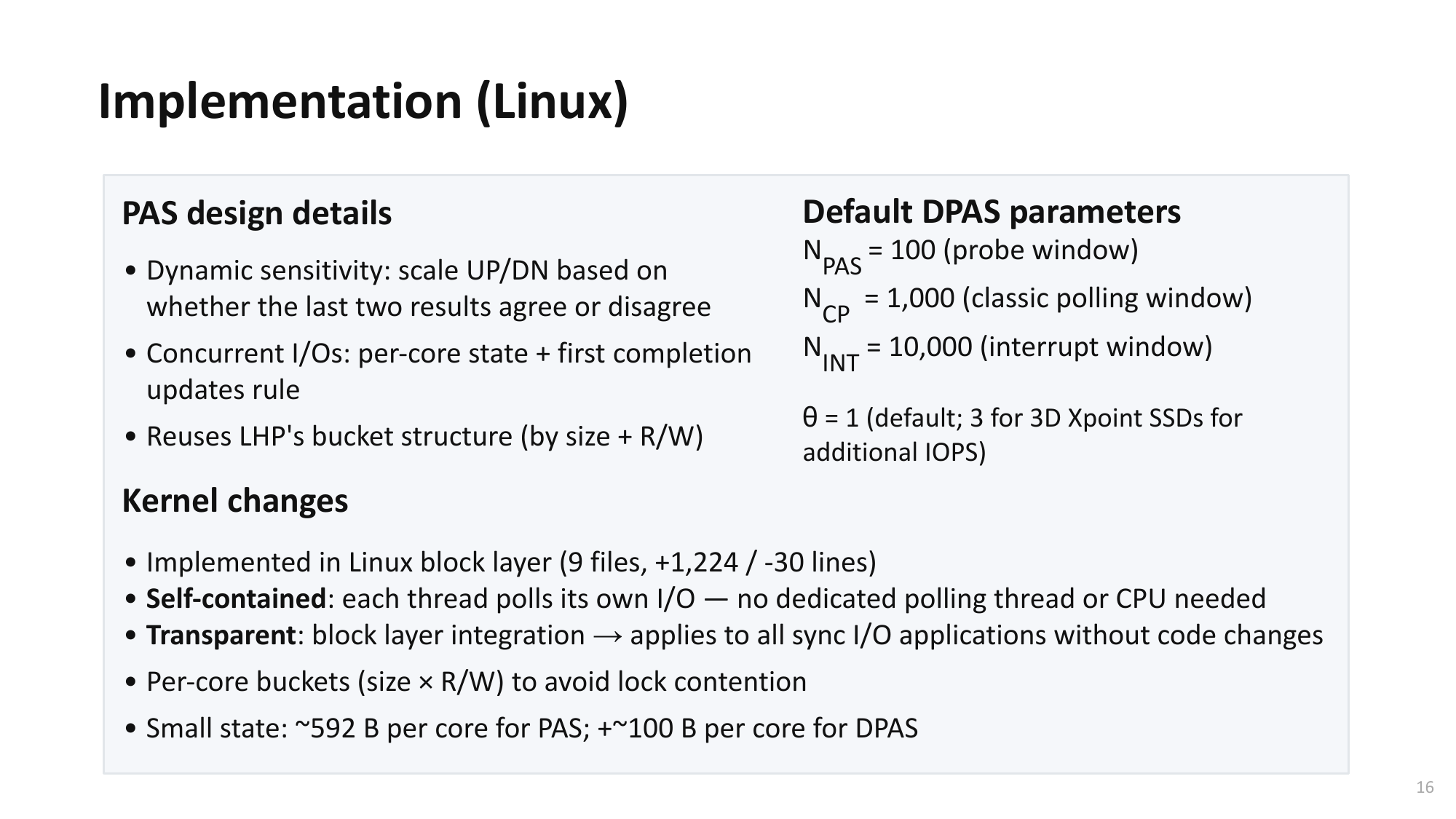
| 4. 알고리즘 도출/보완Algorithm Design | hipri 플래그 주입 기법 설계hipri flag injection technique design — Block layer에서 I/O 요청의 bi_opf에 hipri 플래그를 삽입하는 위치를 탐색— Identified where to insert hipri flag in bi_opf of I/O requests in the block layer — Buffered I/O: readahead 모듈 내 submit_bio() 직전에 hipri 설정— Buffered I/O: set hipri right before submit_bio() in readahead module — Memory mapped I/O: faultaround/readaround 모듈에 동일 적용— Memory mapped I/O: same approach applied to faultaround/readaround modules — blk_poll() 반환 후 hipri를 해제하여 page status 업데이트 부작용 방지— Clear hipri after blk_poll() returns to prevent page status update side effects |
| 5. 구현Implementation | Linux 커널 소스 수정: 12개 파일, +74줄 / -19줄Linux kernel source modification: 12 files, +74 / -19 lines — ext4 파일 시스템 대상, 다른 파일 시스템 확장 용이— Targets ext4 file system, easily extensible to others — Guest OS 커널 + Host OS 커널 양쪽에 적용 가능— Applicable to both guest OS and host OS kernels |
| 6. 시스템 구현System Integration | Host: Intel i7-10700K + 32GB DDR4 + Intel Optane 900P (ULL SSD) — Guest: VirtualBox 6.1.26, Ubuntu 20.04, 커널kernel 5.15 — fio 마이크로벤치마크 + 실제 앱microbenchmarks + real applications (Matlab, Android Studio, Kdenlive 등etc.) |
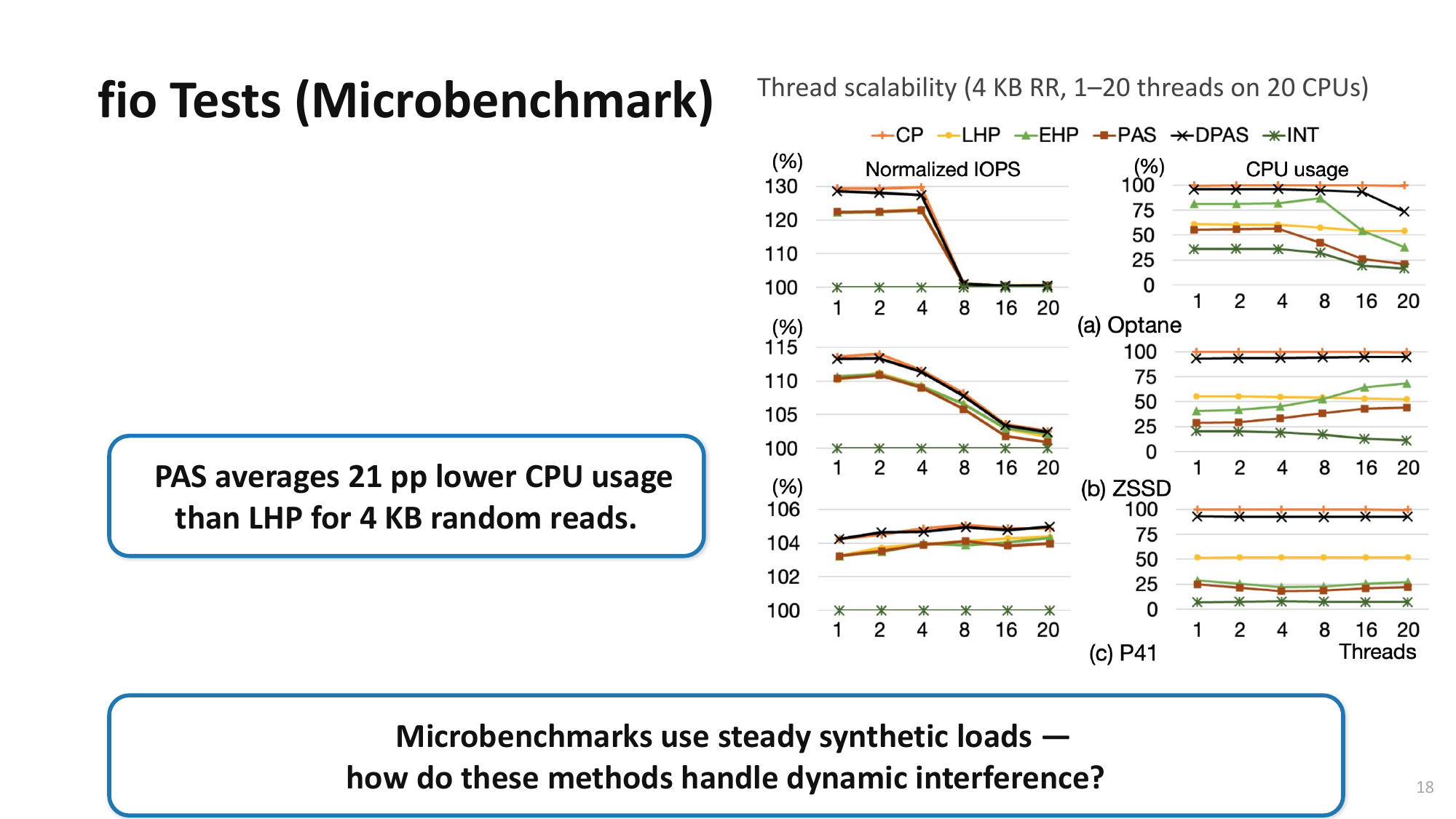
| 7. 성능평가Evaluation | Buffered I/O 4KB random read: 105 → 332 MB/s (3.2배 향상)Buffered I/O 4KB random read: 105 → 332 MB/s (3.2x improvement) — DIO, Buffered, MMAP 모두 vanilla 대비 1.9~3.3배 처리량 향상— DIO, Buffered, MMAP all improved 1.9~3.3x throughput vs. vanilla — 소형 파일 복사 시간 43% 단축 (guest cp), host cp도 20% 단축— Small file copy time reduced 43% (guest cp), host cp also 20% faster — Guest OS I/O 최적화 기능 비활성화 시 메모리 사용량 31~36% 절감— 31~36% memory savings when disabling guest OS I/O optimizations |
| 8. TODO | Remzi의 OSTEP 교과서에 이미 hybrid (two-phased) 접근이 예견됨Remzi's OSTEP textbook already foresaw the hybrid (two-phased) approach — 현재는 항상 poll → 향후 poll/interrupt hybrid (two-phased) 방식으로 확장 가능— Currently always polls → can be extended to poll/interrupt hybrid (two-phased) approach |



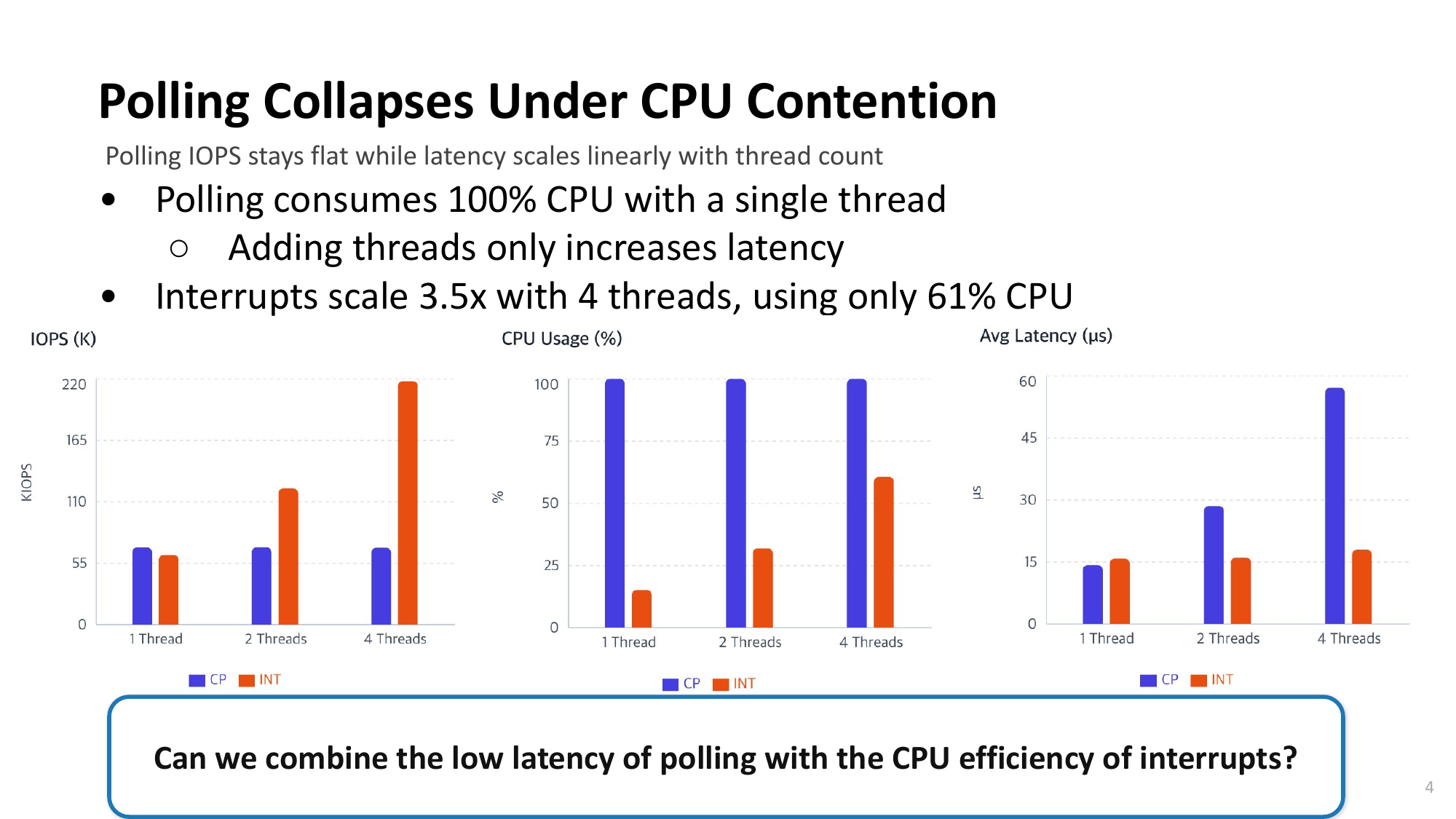
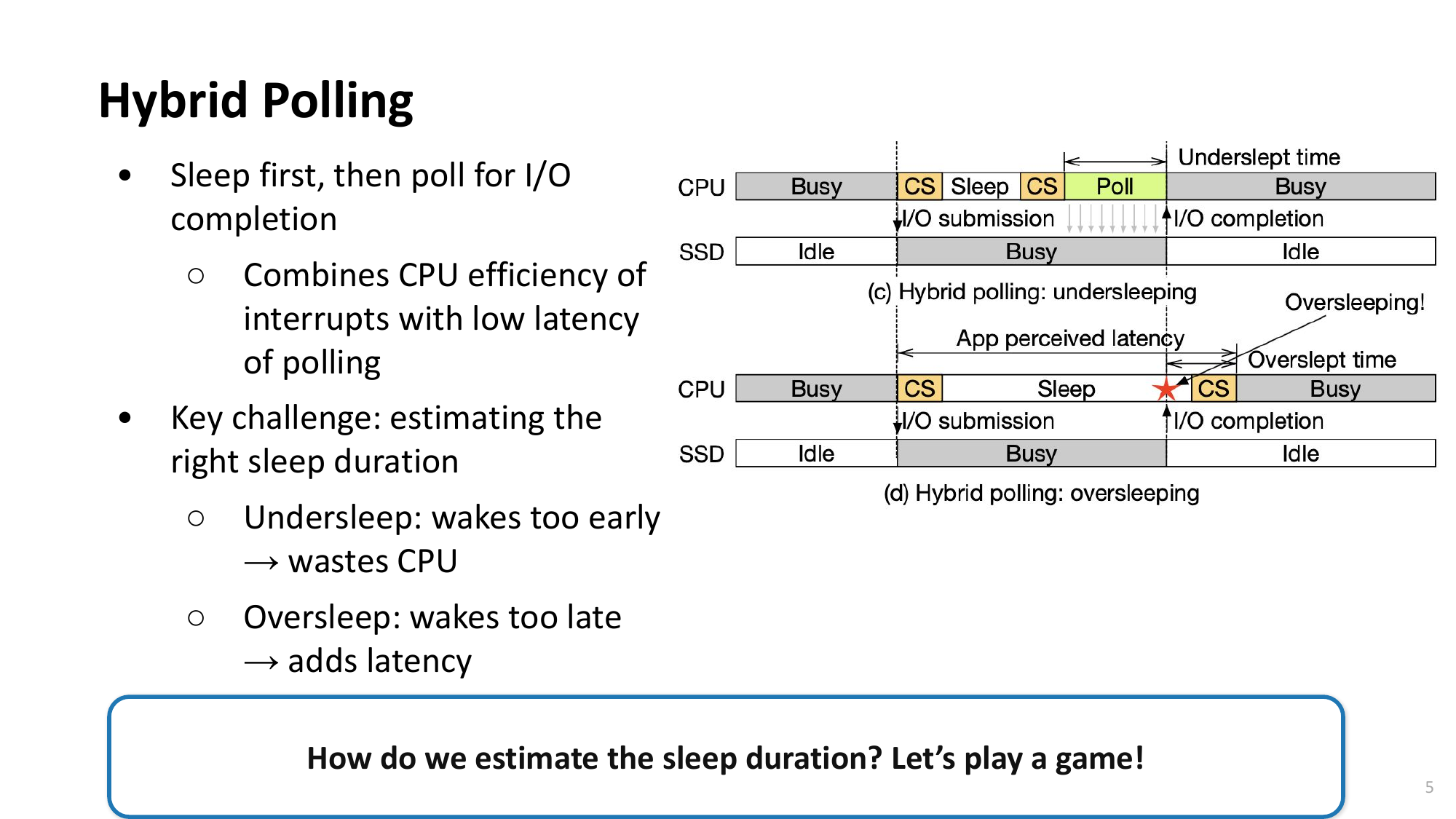


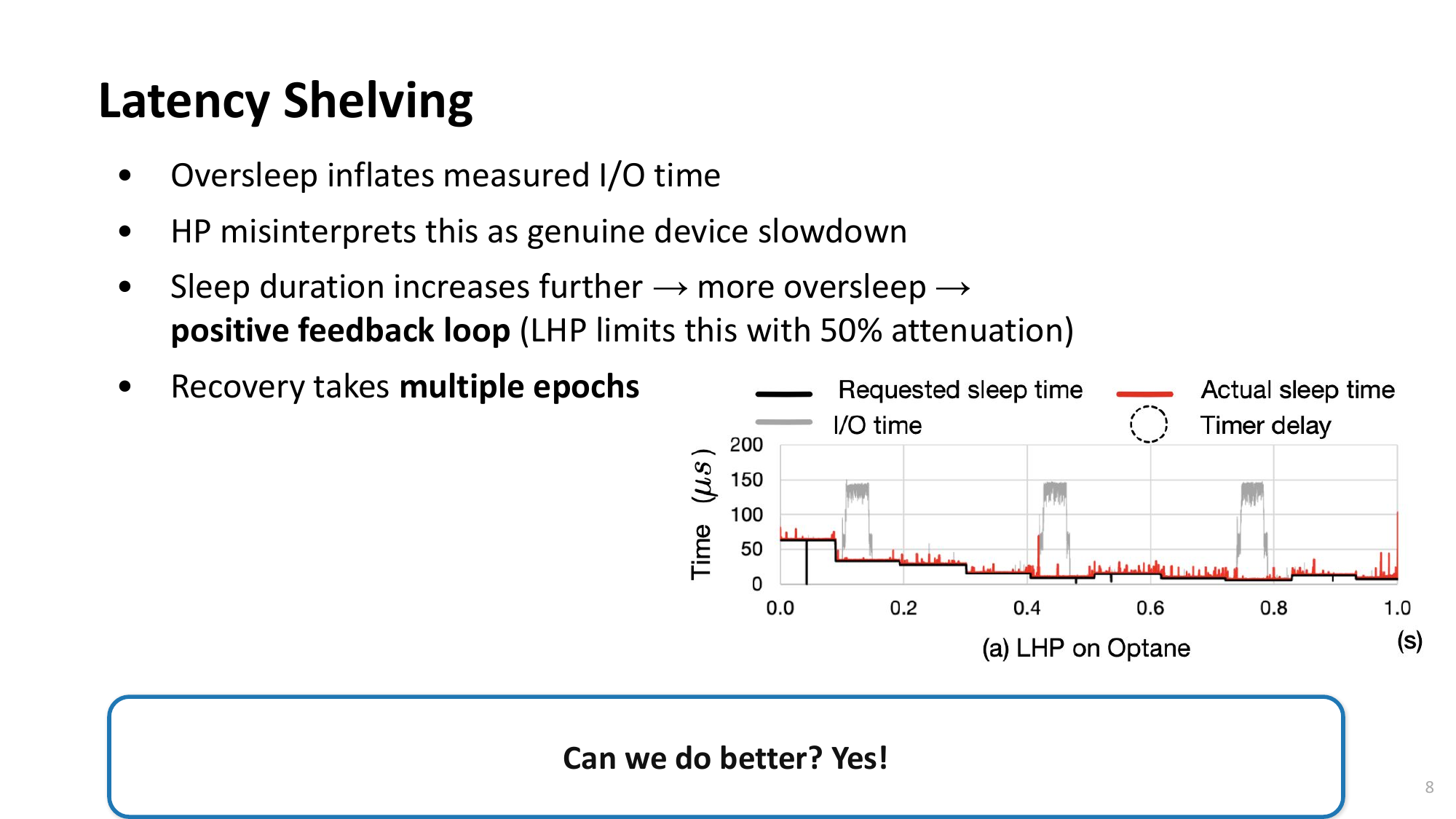

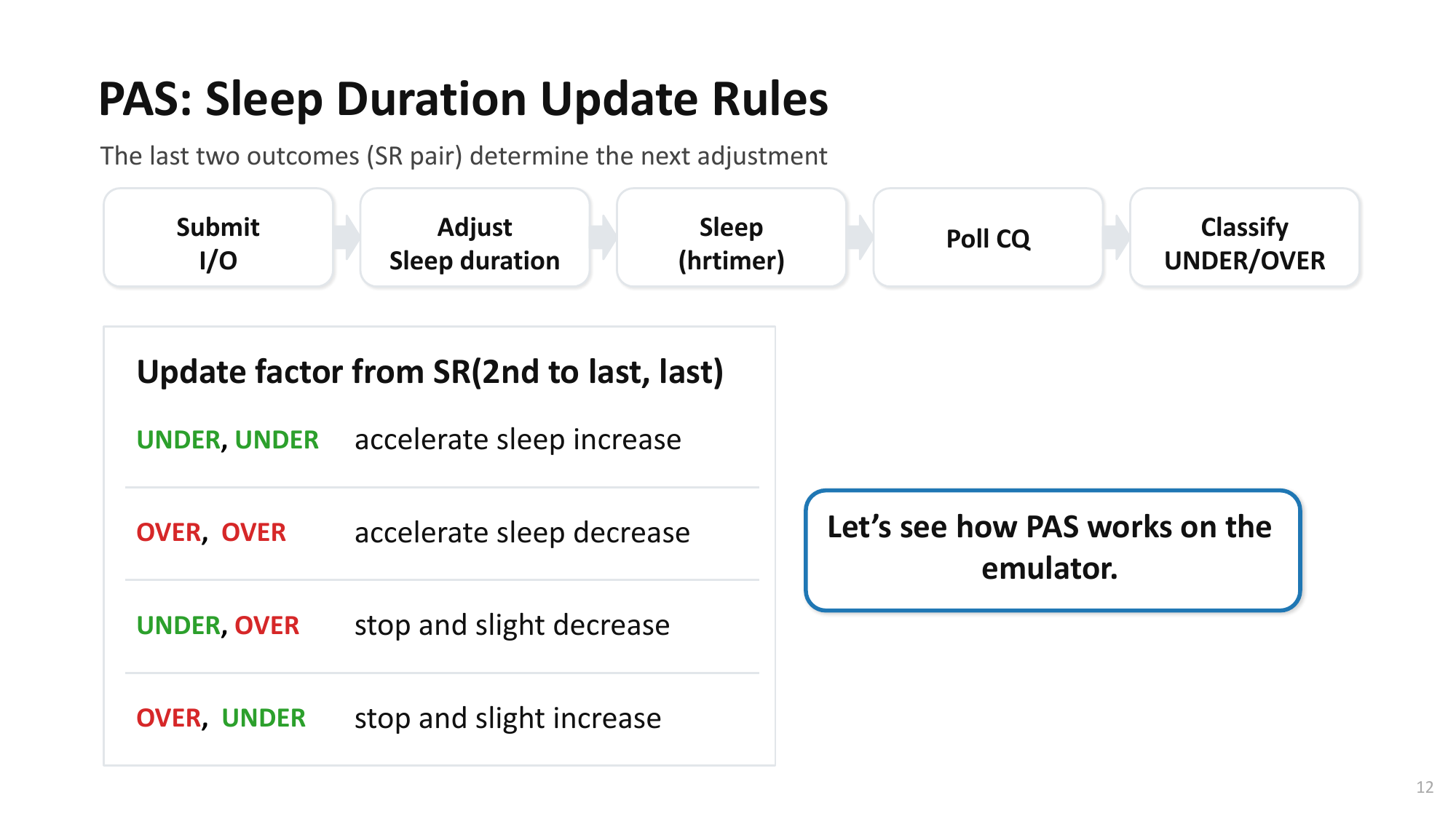
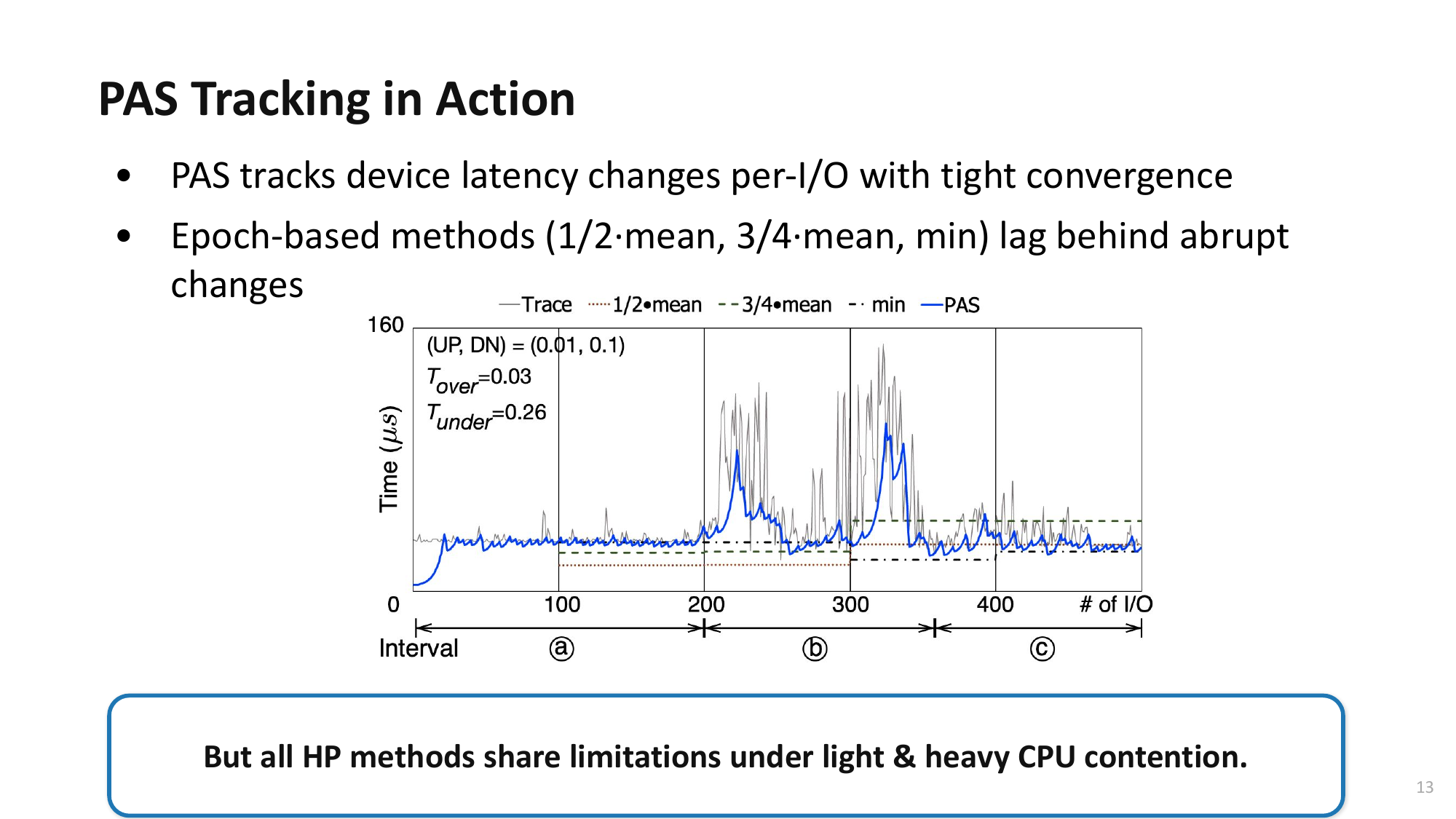



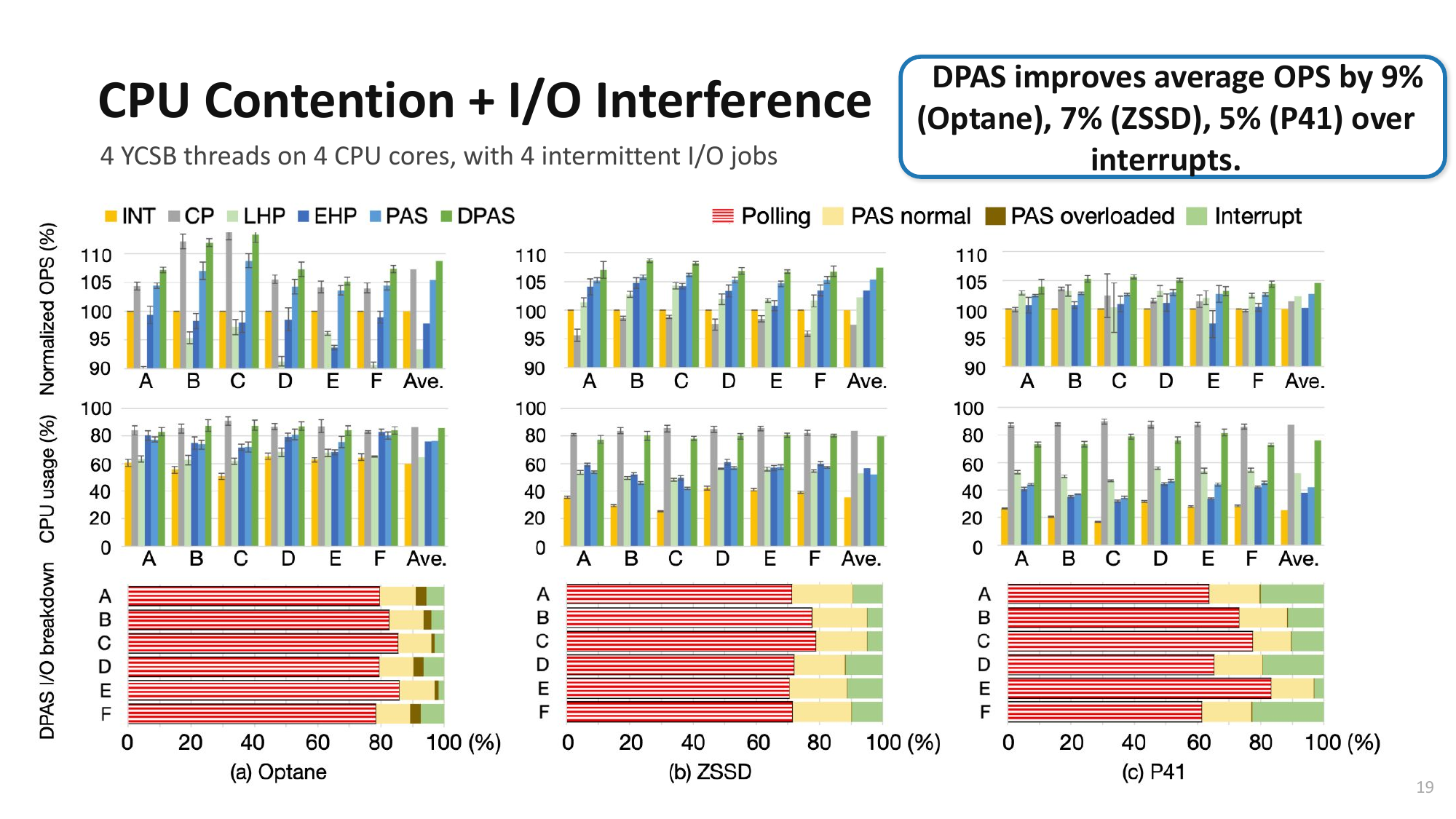
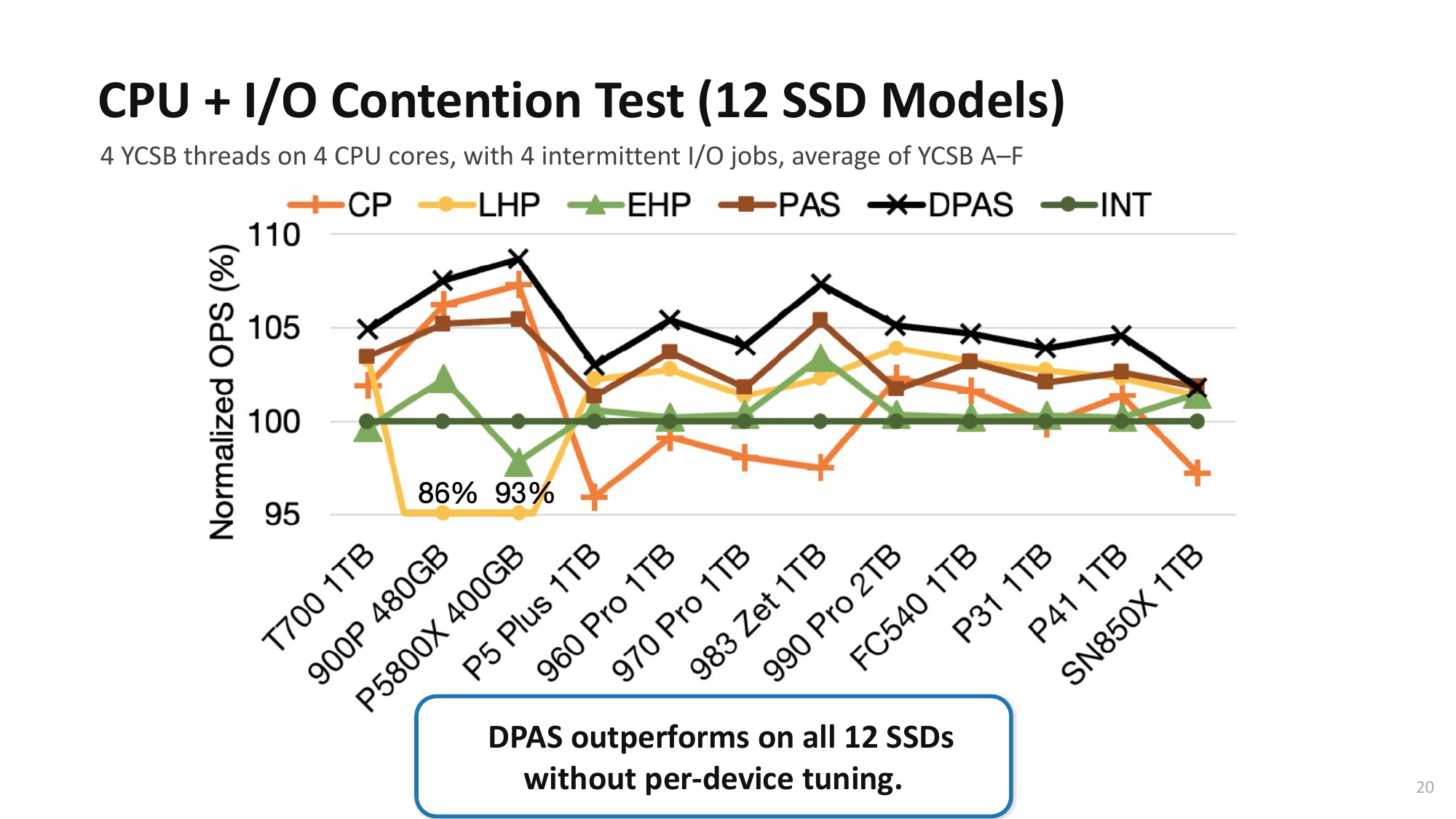
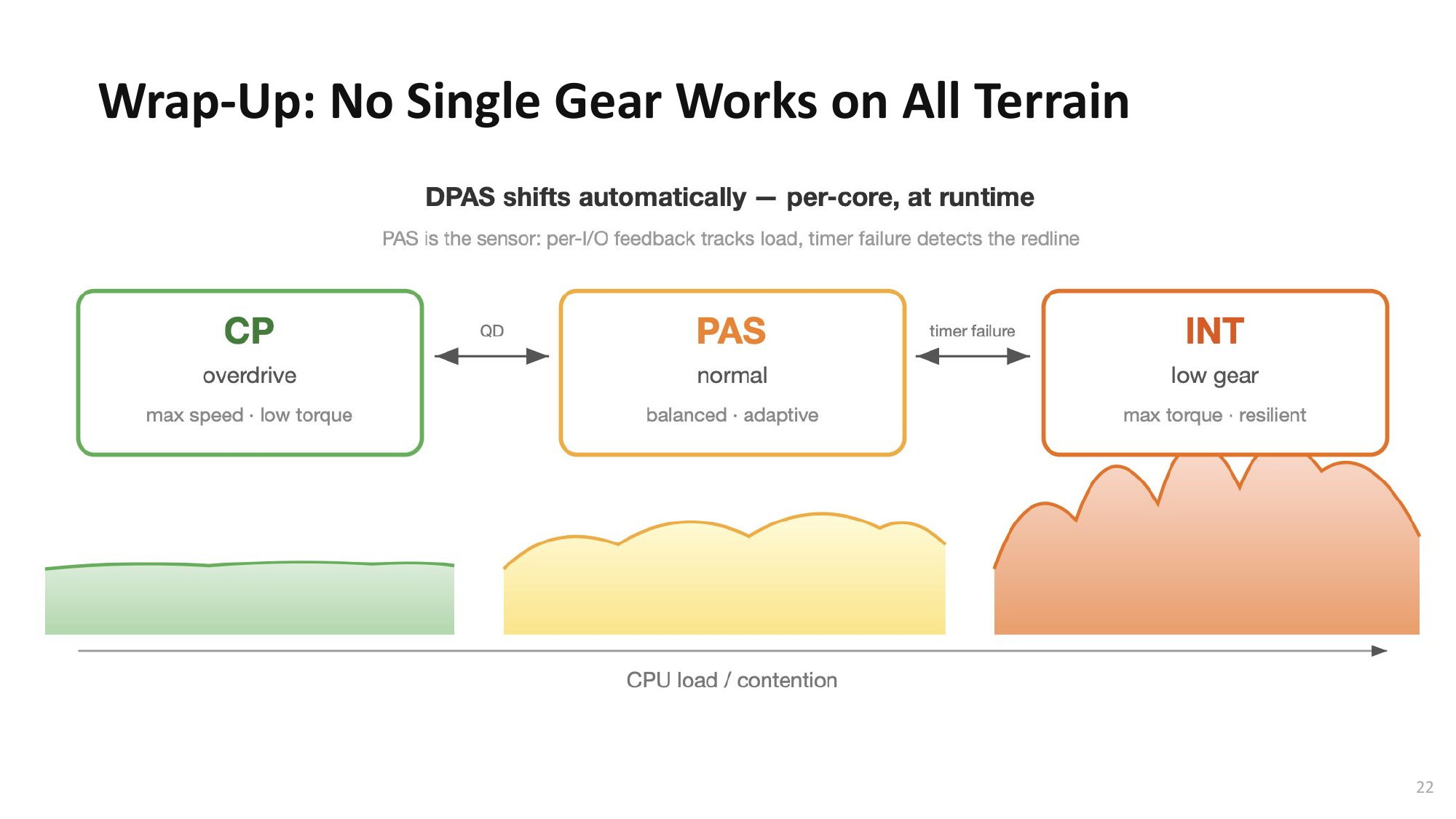
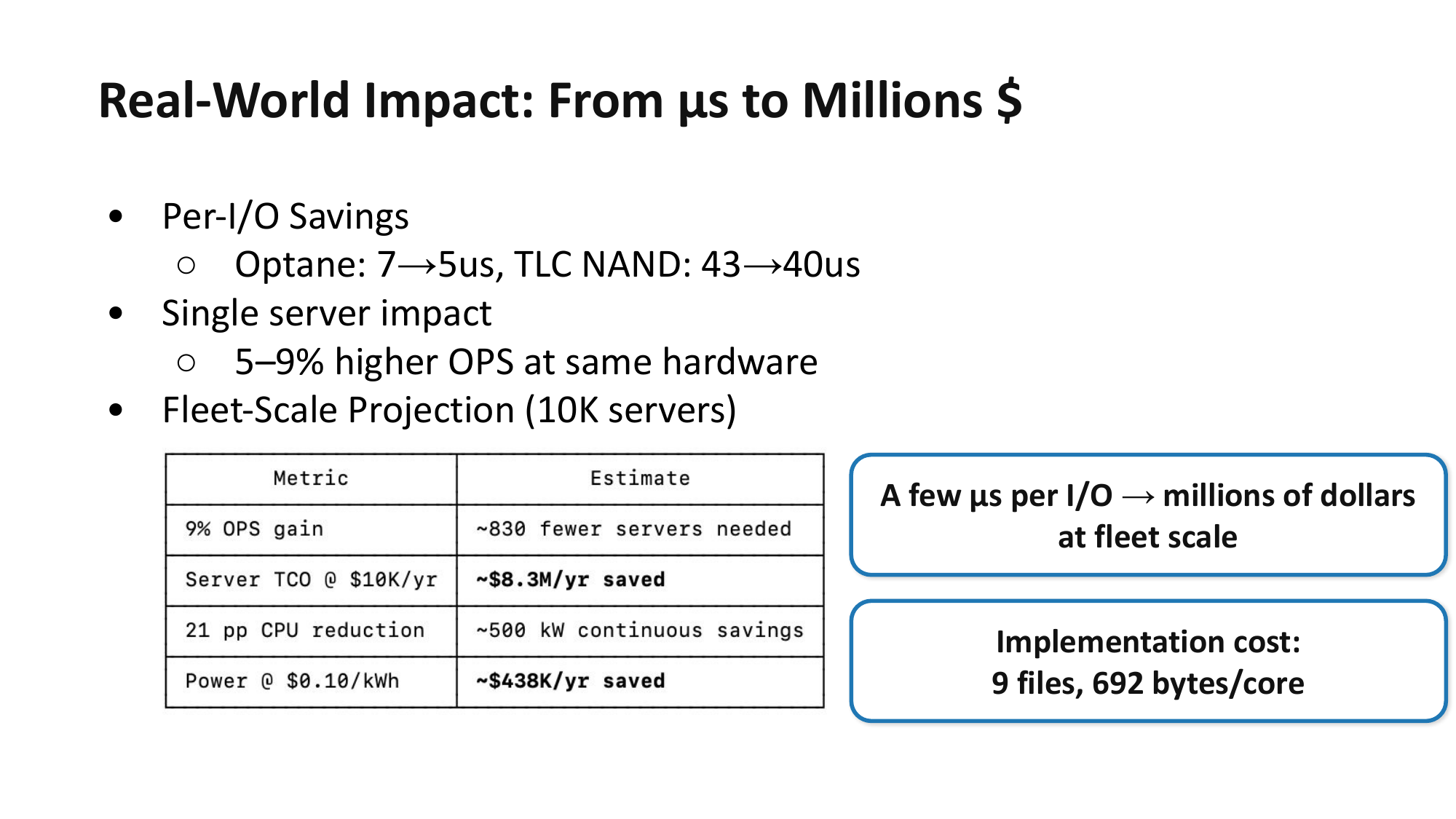
Open Problem: PAS + Interrupt Hybrid
PAS의 한계Limitations of PAS
- PAS의 sleep duration 예측은 완벽할 수 없음
- PAS's sleep duration prediction cannot be perfect
- Oversleep 발생 시 → 앱이 체감하는 latency 증가 불가피
- On oversleep → unavoidable increase in app-perceived latency
- 현재 DPAS: oversleep 감지 후 사후 보정 (다음 I/O부터 adjust)
- Current DPAS: post-hoc correction after detecting oversleep (adjusts from next I/O)
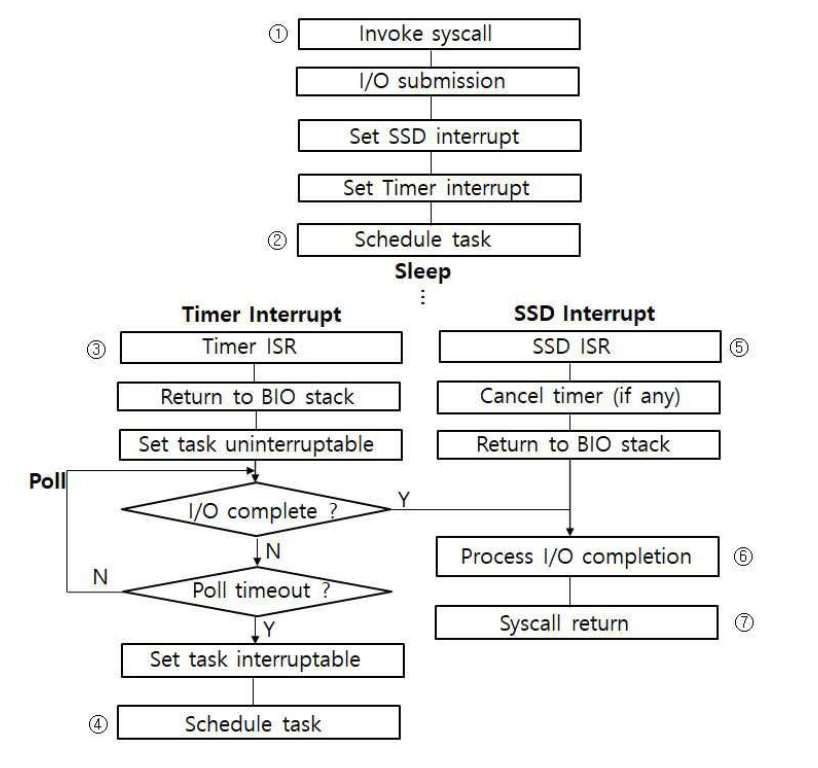
아이디어: Timer + SSD Interrupt 이중 등록Idea: Dual Registration of Timer + SSD Interrupt
- I/O submit 시 timer interrupt와 SSD interrupt를 동시에 설정
- On I/O submit, set both timer interrupt and SSD interrupt simultaneously
- 먼저 발생하는 interrupt에 따라 모드 결정:
- Mode determined by whichever interrupt fires first:
Timer가 먼저 expireTimer expires first
→ PAS 모드: sleep 정확 → poll 후 즉시 완료
→ SSD interrupt 취소→ PAS mode: accurate sleep → poll and complete immediately
→ Cancel SSD interrupt
→ PAS 모드: sleep 정확 → poll 후 즉시 완료
→ SSD interrupt 취소→ PAS mode: accurate sleep → poll and complete immediately
→ Cancel SSD interrupt
SSD interrupt가 먼저 도착SSD interrupt arrives first
→ Oversleep 상황 → interrupt로 즉시 처리
→ timer 취소, latency 손실 최소화→ Oversleep scenario → immediate handling via interrupt
→ Cancel timer, minimize latency loss
→ Oversleep 상황 → interrupt로 즉시 처리
→ timer 취소, latency 손실 최소화→ Oversleep scenario → immediate handling via interrupt
→ Cancel timer, minimize latency loss

등록특허Registered Patent 10-2919645
하이브리드 인터럽트 처리 장치 및 방법Hybrid Interrupt Handling Apparatus and Method
국민대학교산학협력단 · 발명자: 주용수
등록일자: 2026.01.26Kookmin Univ. Industry-Academic Cooperation · Inventor: Yongsoo Joo
Registered: 2026.01.26
하이브리드 인터럽트 처리 장치 및 방법Hybrid Interrupt Handling Apparatus and Method
국민대학교산학협력단 · 발명자: 주용수
등록일자: 2026.01.26Kookmin Univ. Industry-Academic Cooperation · Inventor: Yongsoo Joo
Registered: 2026.01.26